
Beyond RAG: Building Production-Grade AI Coworkers for the Enterprise (feat. Karl Simon)
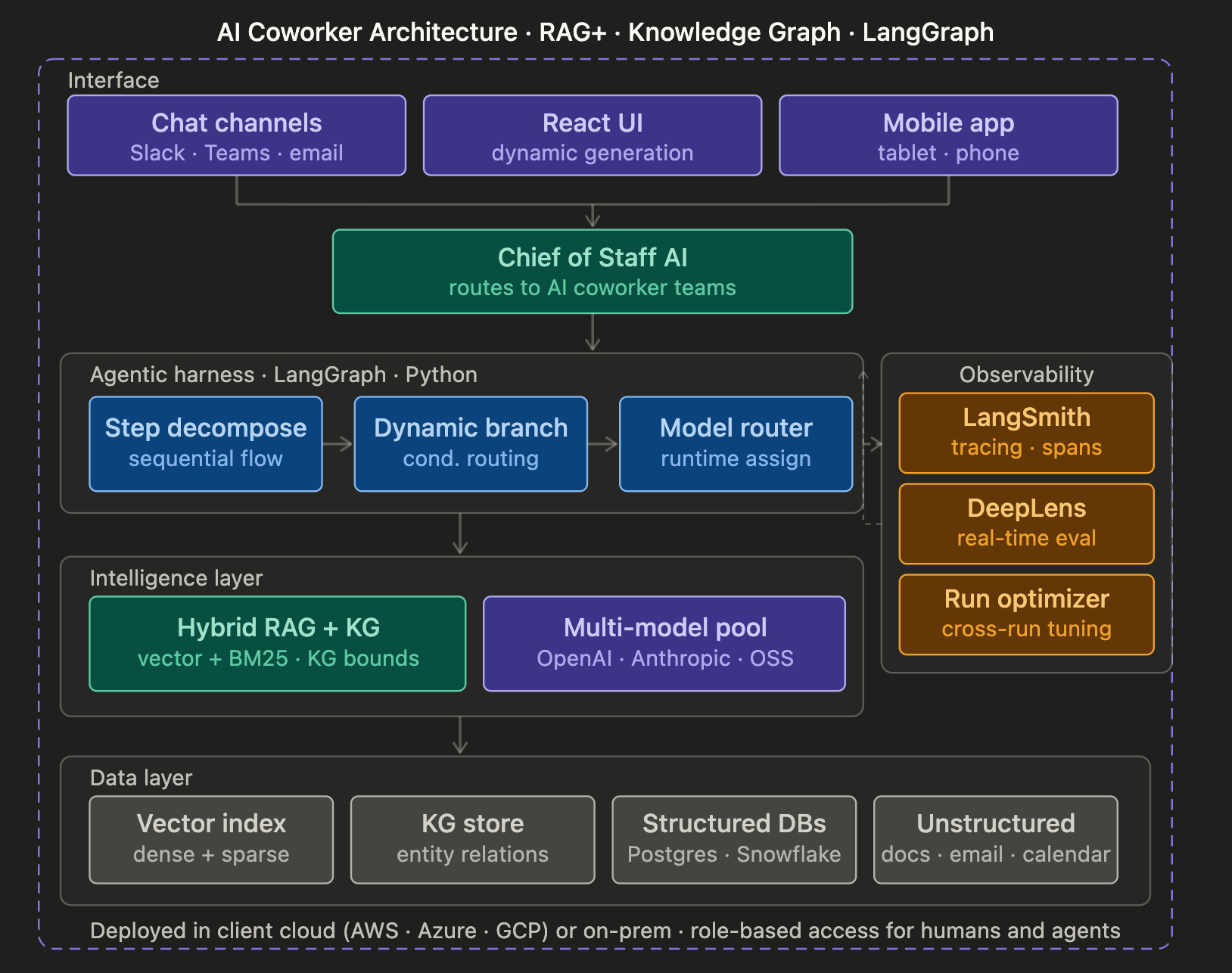
Enterprise AI systems require knowledge graphs, agentic orchestration, and rigorous engineering discipline to deliver reliable, production-grade automation across complex workflows.

Based on a conversation with Karl Simon, Co-founder and CTO of Subatomic.
There is a meaningful difference between pasting a problem into ChatGPT and deploying an AI system that autonomously orchestrates multi-step workflows across a regulated enterprise. Karl has spent the last several years working in that gap — building what he calls “AI coworkers” for wealth management firms and manufacturers. This article unpacks the architectural decisions, engineering philosophy, and organizational implications behind that work.
Podcast
Beyond RAG: Building Production-Grade AI Coworkers for the Enterprise — on Apple and Spotify.
Summary
The Problem With Vanilla RAG — why knowledge graphs are necessary beyond hybrid BM25+vector retrieval
The Agentic Harness — multi-model routing, observability, and the two-tier feedback loop (DeepLens + aggregate optimization)
The Tech Stack — Python, LangChain/LangGraph/LangSmith, React, database-agnostic deployment, and in-client cloud architecture
Two Case Studies — wealth management meeting prep (8,000 hours eliminated) and the field service diagnostic reporting app
Human-AI Engineering Teams — the 80/20 assembly line, TDD enforced at the AI layer, and developers as AI coworker managers
Interfaces for Human and Agent Consumers — dynamic dashboard generation and why Markdown outperforms JSON for agent-to-agent handoffs
The Broader Shift — what changes (mid-management, SaaS economics, the value of specification over implementation) and what doesn’t (core engineering discipline)

The Problem With Vanilla RAG
Retrieval-Augmented Generation is the obvious starting point for any system that needs to answer questions grounded in proprietary data. Hybrid RAG — combining dense semantic search with sparse BM25 indexing — improves recall over pure vector similarity. But Simon argues that even hybrid RAG is insufficient for enterprise contexts, because it lacks the domain structure to know which retrieved chunks are actually relevant to the question at hand.
Consider a wealth management firm preparing for a quarterly client review. Relevant information is scattered across custodial platforms, risk management systems, retirement and estate planning tools, tax software, CRM records, email, calendar, and document storage. A naive RAG query returns semantically similar chunks, but it has no way to understand the relational context: that a particular estate plan is tied to a specific client’s risk tolerance, which is in turn constrained by a life event recorded in the CRM.
Subatomic’s answer is what Simon calls “RAG plus”: a knowledge graph that encodes the domain model — entities, relationships, and their interdependencies — and then uses that graph to bound and contextualize retrieval. When a query comes in, it is not simply sent to a vector index. Instead, the knowledge graph provides a contextual boundary that filters and ranks retrieved chunks according to their position in the domain model. The result is what Simon describes as “contextually guardrailed” retrieval — semantically relevant and domain-coherent.
Building the knowledge graph correctly is non-trivial. It requires capturing how services interconnect, how client profiles relate to financial instruments, and how different regulatory and planning concerns interact. “We handle the tricky,” Simon says. “We handle the complex.”
The Agentic Harness: Why Prompting Alone Falls Short
A common misconception Simon encounters is that a well-crafted prompt to a capable foundation model is functionally equivalent to a purpose-built agentic system. It is not — and the gap becomes obvious at scale.
Even the best publicly benchmarked models achieve accuracy rates well below the 90th percentile on complex, multi-step tasks when given only a single-pass prompt. The core issue is that a prompt is stateless and monolithic. It cannot dynamically branch on intermediate findings, consult external knowledge mid-execution, or route sub-tasks to specialized models.
An agentic harness solves these problems by decomposing complex workflows into discrete steps, each of which can independently reason, retrieve, and act. Within any given step, the harness can branch based on intermediate outputs — routing a technical diagnostic question differently from a billing inquiry, for example. This structure also enables:
Multi-model routing. Subatomic deploys multiple models simultaneously — both commercial (OpenAI, Anthropic) and open-source — and assigns tasks to models based on fit. A large frontier model handles nuanced reasoning; a fine-tuned smaller model handles a narrow classification step faster and more cheaply. This is not just cost optimization; smaller specialist models often outperform larger generalists on tasks they were trained for.
Observability as a first-class citizen. Subatomic uses LangSmith for baseline tracing and augments it with extended audit logs that surface the full chain of reasoning to clients. Every execution records which workflow steps were invoked, what reasoning was applied, and what intermediate answers were produced. This matters in regulated industries where you cannot simply say “the AI decided.”
Continuous optimization. Simon describes a two-tier feedback loop. At the request level, a dedicated AI coworker called DeepLens evaluates the execution in real time, checks it against expected reasoning patterns, and self-corrects before returning a final answer. At the aggregate level, patterns across executions are analyzed for accuracy, faithfulness, consistency, and cost anomalies — and the knowledge graph and retrieval configuration are updated accordingly.
The Tech Stack
Subatomic’s stack reflects a bias toward flexibility and interoperability over vertical lock-in.
Languages and frameworks. Python is the primary language, chosen in part because it is common enough that clients who want a co-management support model can participate. LangChain is the primary orchestration framework; LangGraph handles graph-based agent topology; LangSmith provides tracing.
Frontend. React components, with the capability to dynamically generate UI elements at runtime based on the nature of a request — not just serve a static dashboard.
Databases. Rather than imposing a fixed data store, Subatomic adapts to whatever the client already operates: Postgres by default, but also Snowflake, Databricks, SQL Server, Oracle, and others. This is less about maintaining a library of pre-built connectors and more about code generation: Subatomic’s AI coworker engineers can produce dialect-specific code for a given target system rapidly, including transformations between structural paradigms (relational, key-value, graph) when a client is migrating or consolidating.
Deployment. Subatomic is not a SaaS product. It deploys into the client’s own cloud account (AWS, Azure, GCP) or on-premises, ensuring that client data never leaves their security perimeter. Security and auditability are designed in from the start, not bolted on.
Architecture in Practice: Two Case Studies
Wealth Management: Client Meeting Preparation
The flagship use case eliminates the manual labor of aggregating information before a client meeting. An advisor’s relevant data — portfolio positions, risk profile, tax exposure, estate planning status, recent correspondence, CRM notes — is scattered across at least six distinct systems. Previously, assembling a 360-degree view required hours of manual extraction and synthesis.
With the Subatomic system in place, the AI coworker traverses the knowledge graph to identify all entities related to the client, retrieves relevant documents and structured records via hybrid RAG, and produces a synthesized briefing scoped to the meeting’s agenda. The system eliminated approximately 8,000 hours of labor annually across one firm’s advisor team.
Field Service: Automated Diagnostic Reports
A high-end commercial oven manufacturer needed to standardize the quality of field service reports. Technicians would spend multiple days on-site diagnosing complex failures; the reports they produced varied significantly in quality and structure.
Subatomic built a mobile application (tablet and phone form factors) that guides technicians through a structured diagnostic workflow. The app collects text, photos, and video as a technician progresses through diagnosis steps. Once all data is captured, an agentic system — pulling in the relevant maintenance documentation via hybrid RAG, bounded by the product’s knowledge graph — synthesizes a formatted report that reflects the company’s preferred documentation practices.
What makes this more than a form-filling tool is the dynamic branching. The workflow adapts based on the category and complexity of the fault being diagnosed, surfacing different sub-procedures and reference documents depending on intermediate findings.
Human-AI Engineering Teams
Subatomic operates with 13 human engineers and over 100 AI coworkers. The ratio was not always this way; it inverted over the past year. This inversion has specific implications for how the team is structured and how software gets built.
The 80/20 assembly line. Subatomic has two internal AI coworker platforms: Nexus for data engineering tasks, and Nucleus for workflow orchestration. Together, they generate approximately 80% of the codebase for a given client engagement. Human engineers handle the final 20% — the layer that is specific to the client’s operating procedures, cognitive patterns, and regulatory context. Below that custom layer are reusable domain modules (industry-standard patterns and entity models) that are shared across engagements, though never identical codebases between clients.
Test-driven development enforced at the AI layer. Simon is emphatic about test-driven coding. Functional and technical test conditions are specified before any code is generated, and the AI coworkers are required to produce code that satisfies those conditions. This is not just a quality mechanism — it is an accountability mechanism. When testing is separated into a distinct role, he argues, it diffuses responsibility. When the code-generating system is also responsible for passing the tests it was given, accountability stays in one place.
Developers as AI coworker managers. The practical role of a human engineer at Subatomic has shifted from writing code to managing the AI coworkers that write code — reviewing output, specifying constraints, catching edge cases that automated generation misses. Software design patterns and data engineering patterns still matter; they are what make an engineer capable of evaluating whether the AI’s output is durable for production conditions. Vibe-coded output, in Simon’s assessment, almost always lacks the security hardening and edge-case handling required for real production environments.
Interfaces for Human and Agent Consumers
The field service application raised an important design question: should the interface be a structured form or a conversational interface? Subatomic initially built headless (chat-only) interfaces and found strong adoption among technically sophisticated users. When clients requested dashboards, the team did not simply add static charts — they built dynamic visualization generation. An advisor can ask a natural-language question and receive both a synthesized answer and an auto-generated dashboard that surfaces the key metrics supporting that answer.
For agent-to-agent communication, Simon points to a structural shift away from JSON as the interchange format toward Markdown. Large language models synthesize Markdown more reliably than JSON when passing context between agents; JSON-encoded intermediate state produces less consistent output on the receiving end. This has practical implications for how agentic pipelines are designed: when agents need to hand off context to one another — whether within the same system or across organizational boundaries in something like a supply chain — Markdown-structured summaries outperform raw structured data as the information carrier.
Role-based access control applies equally to human and agent callers. A registry of accessible tools and functions is maintained per caller identity, regardless of whether that caller is a human in Slack or an upstream agent.
The Broader Shift: What Changes and What Does Not
The fundamental practices of software engineering — design patterns, data modeling, security architecture, observability — have not changed. What has changed is the ratio of human effort required to produce a working implementation. The “hello world to production” journey is dramatically shorter when 80% of the scaffolding is generated. This does not mean the scaffolding does not need to be reviewed; it means the review is more valuable than the generation.
Mid-management may be disproportionately affected. AI systems that unify information across organizational silos — eliminating the need to escalate requests through multiple layers to get a cross-functional answer — reduce the coordination function that mid-management has historically provided. Simon estimates 80% of director and senior-manager level roles could be affected by 2028.
The SaaS model faces structural pressure. If an organization can instruct an AI coworker to build a CRM tailored to its own workflows — rather than licensing a general-purpose one and customizing around its constraints — the economic case for many vertical SaaS products weakens. Subatomic itself has replaced its own CRM with an internally generated alternative.
The most durable engineering skill, in this view, is not the ability to write code. It is the ability to specify what correct code looks like — to define the test conditions, the architectural constraints, and the security requirements that a generated implementation must satisfy. That specification skill requires deep domain and systems knowledge. It is also the hardest to automate.
FAQ
Architecture & Retrieval
Q: What is “RAG plus” and how does it differ from standard RAG?
Standard RAG retrieves documents by semantic similarity. Hybrid RAG adds sparse keyword indexing (BM25) to improve recall. “RAG plus” goes a step further by layering a knowledge graph on top of retrieval — the graph encodes domain entities and their relationships, and retrieval is bounded within that contextual structure. This means the system does not just find semantically similar chunks; it finds chunks that are coherent within the domain model relevant to the query.
Q: Why is a knowledge graph necessary? Can’t a well-structured vector index do the same job?
A vector index captures semantic proximity, not relational structure. In a domain like wealth management, the relevance of a document depends on how its subject relates to other entities — a tax document is relevant to a client meeting only if it is connected to that specific client’s profile and current planning objectives. A knowledge graph makes those connections explicit and traversable. Without it, retrieval is context-blind.
Q: What interchange format works best for agent-to-agent communication?
Markdown. JSON was an earlier default for passing state between agents, but large language models produce less consistent output when synthesizing from JSON-encoded context. Markdown-structured summaries yield more reliable downstream reasoning, whether the receiving agent is internal to the same pipeline or external across an organizational boundary.
The Agentic Harness
Q: Why not just use a foundation model directly with a detailed prompt?
A single-pass prompt is stateless and monolithic. Even well-designed prompts to top-tier models achieve accuracy below 90% on complex, multi-step tasks. An agentic harness decomposes the problem into discrete steps, enables dynamic branching on intermediate results, consults external knowledge mid-execution, and routes sub-tasks to purpose-fit models. The compounding effect across many steps makes the difference between a prototype and a production system.
Q: How does multi-model routing work in practice?
Tasks are evaluated at runtime and assigned to the model best suited for that specific sub-task — a large frontier model for nuanced reasoning, a smaller fine-tuned model for a narrow classification step. The goal is both cost efficiency and accuracy: smaller specialist models often outperform larger generalists on tasks they were trained for. Sending every request to the largest available model is both wasteful and sometimes less accurate.
Q: What does observability look like inside an agentic system?
At the request level, every execution records which workflow steps were invoked, what reasoning was applied, and what intermediate answers were produced before the final output. A dedicated evaluation layer checks the execution against expected reasoning patterns in real time and self-corrects before returning a result. At the aggregate level, patterns across executions are analyzed for accuracy, faithfulness, consistency, cost, and standardization — and the system configuration is updated accordingly.
Q: How do you prevent an agentic system from hallucinating or going off-rails?
Several mechanisms work together: the knowledge graph bounds retrieval to contextually relevant information; workflow steps are pre-defined with explicit logic branches rather than open-ended generation; test conditions are specified upfront and the system must satisfy them; and a real-time evaluation layer audits the execution chain before output is returned. Security and observability are not add-ons — they are designed into the harness from the start.
Deployment & Integration
Q: Is this a SaaS product that customers sign up for?
No. The system deploys into the client’s own cloud environment (AWS, Azure, GCP) or on-premises. The client is the tenant of the account. This ensures data never leaves the client’s security perimeter and allows the deployment to conform to the client’s existing security controls rather than requiring them to adapt to a third-party SaaS boundary.
Q: How does the system handle clients with different database infrastructure?
Rather than requiring a specific database, the system generates dialect-specific code for the target data store — Postgres, Snowflake, Databricks, SQL Server, Oracle, and others. When a client is migrating between platforms (e.g., Redshift to Snowflake), the system can convert the relevant query logic with minimal impact. When the underlying data structure changes (e.g., relational to key-value), adapter code handles the transformation. The guiding principle is minimum disruption to existing architecture.
Q: Can the system integrate with existing communication tools like Slack or Teams?
Yes. A “chief of staff” layer acts as the coordination point for all AI coworker teams and is accessible from standard communication channels — Slack, Teams, email, SMS — in addition to a dedicated UI. This broadens adoption because users can interact with the system wherever they already work, without context switching into a separate application.
Engineering Teams & Development Practices
Q: Do you still need software engineers if AI generates 80% of the code?
Yes, and for a specific reason: the value of an engineer has shifted from writing code to specifying what correct code looks like. Defining test conditions, architectural constraints, security requirements, and edge-case behavior requires deep systems knowledge. Vibe-coded output — generated without those constraints — is consistently more fragile in production: it misses security hardening, fails on edge cases, and is difficult to audit. Someone with engineering discipline needs to own the final 20% and verify the 80%.
Q: How has test-driven development changed with AI code generation?
Test conditions are now specified as inputs to the AI coworker before code generation begins, not written after the fact. Functional requirements come from business stakeholders; technical requirements (performance, security, edge cases) come from engineers. Both feed into the planning and design phase before any code is produced. This approach preserves accountability: the system that generates the code is also responsible for satisfying the tests, rather than diffusing that responsibility across separate roles.
Q: What is the practical role of a human engineer on an AI-augmented team?
Human engineers function as managers of AI coworker teams. They specify what needs to be built, define the guardrails and test conditions, review generated output for durability and correctness, and handle the client-specific customization layer that requires judgment about that organization’s particular workflows and constraints. The core software design and data engineering knowledge is what makes them capable of doing that review effectively.
Q: Is vibe coding viable for production systems?
For non-critical applications where downtime is tolerable and accuracy requirements are loose, vibe coding can reach a functional state quickly. For systems operating in regulated industries, handling financial or medical data, or requiring consistent behavior across many users, it is not sufficient on its own. The generated code needs review by someone who can evaluate security posture, architectural soundness, and coverage of production edge cases — and who can be accountable to clients when something breaks.
Interfaces & User Experience
Q: Should enterprise AI systems use chat interfaces or traditional dashboards?
Both, dynamically. A chat-first interface enables natural-language access and improves adoption because users can interact without learning a new UI. But when a response warrants visualization — key metrics, comparative data, trend analysis — the system should auto-generate the appropriate dashboard for that specific query rather than serving a static pre-built view. Static dashboards answer the questions you anticipated; dynamic generation answers the ones you did not.
Q: How should UX be designed for systems that serve both humans and agents?
The interface layer needs to produce responses appropriate to the consuming audience. For human users: contextually relevant answers with dynamic visualization where useful. For agent consumers: Markdown-structured outputs that downstream models can synthesize reliably. Role-based access control applies equally to both — a registry of accessible tools and functions governs what any given caller, human or agent, is permitted to invoke.
Organizational Impact
Q: Which roles are most affected as AI takes on more knowledge work?
Engineering is the most visible impact so far, with AI systems generating the majority of code and reducing the human headcount needed for a given output level. Mid-management may be equally or more affected: AI systems that unify information across organizational silos perform the coordination function that middle management has historically provided, reducing the need to escalate requests through multiple layers to get a cross-functional answer.
Q: What happens to vertical SaaS products as AI coworkers become more capable?
The economic case for many vertical SaaS products weakens when an organization can instruct an AI coworker to build a fit-for-purpose tool tailored to its own workflows — without paying per-seat licensing fees or working around a vendor’s constraints. Organizations that are AI-first are already building internal replacements for CRM, reporting, and workflow tools rather than licensing external products. This trend is likely to accelerate as AI coworker code generation becomes more reliable.
Q: What is the most durable skill for engineers going forward?
The ability to specify what correct behavior looks like: defining test conditions, architectural requirements, security posture, and the edge cases a system must handle. This is harder to automate than code generation because it requires understanding the domain, the failure modes, and the accountability structure of the system being built. Engineers who develop strong specification skills will function effectively as the managers and reviewers of AI-generated code regardless of how capable automated generation becomes.